HEVC Decoding on the RPI4 Optimized With arm64 Assembly Code

As some of you might recall I discussed several APIs in the previous blog post. Admittedly I focused more on libvaapi and the ffmpeg API in that post but also invested a few hours on attempting to utilise the Raspberry PI 4 video encoding and decoding hardware. Unfortunately with success limited to 1080p and h264.
Having revisited the topic of HEVC decoding on the Raspberry PI 4 recently, I stumbled across a few limitations and attempted to resolve a few of them. In fact without these changes a 64bit linux distribution on the PRI4 will not be able to decode 2160p HEVC content with more than ~7fps, which of course does not satisfy most use cases. Jumping a bit ahead I had to implement an arm64 version of the SAND layout to regular frame conversion in order to achieve above 30fps. While still not having solved all of the challenges and limitations with this approach, it might get us closer to having a good HEVC experience on the RPI4. Follow the discussions about the proposed improvements on GitHub: av_rpi_sand8_lines_to_planar_y8/c8: Add arm64 assembly implementation. (Update on the 18th of January: The changes have already been accepted and are merged to the drm_prime_1 branch.)
But before jumping ahead to the solution in detail, let’s discuss the actual steps on how to enable the HEVC decoding first.
Note: This is a significantly rewritten and extended version of an article I published about two weeks ago on this blog. You can check out the original version here: Web Archive: HEVC Decoding on the Raspberry PI 4/arm64. This new article focuses on not only accessing the hardware decoder but attempts to improve the software side be resolving some of the performance limitations. Nevertheless it also contains the compilation instructions for ffmpeg and required configuration changes mentioned in the original blog post.
HEVC Hardware Decoder
As discussed in one of the previous blog posts, the stateful V4L2 API can be used to decode and encode H264 video content with resolutions up to 1080p. This works well also on 64bit operating systems and is supported by upstream ffmpeg. You probably noticed the decoders and encoders with an _v4l2m2m postfix in their names. The new HEVC decoder has to be accessed by different means. Fortunately there is a linux kernel module called rpivid, which makes the functionality available through the stateless V4L2 request API. Distributions shipping a recent enough kernel driver, already include this kernel module. I used Ubuntu 20.10 64bit for these experiments, but the 20.04 release should be fine as well.
Additionally to having the kernel load the correct module we also need a patched version of ffmpeg. The upstream release doesn’t yet include support for the V4L2 request API and we also need additional Raspberry PI specific features. All of this is available in a fork on Github: rpi-ffmpeg/dev/4.3.1/drm_prime_1.
Compiling this release can be achieved with the instructions below. The important steps are preparing the correct kernel headers and configuring the correct build options. Especially important is also the –enable-sand flag. If it isn’t enabled, ffmpeg will compile but won’t be able to handle the decoded frames correctly. This is because the HEVC decoder produces frames with a certain layout we will discuss in more details further down in this post.
Enough said, here are the instructions:
# 0. Prepare the system
#enable device overlay
sudo echo "dtoverlay=rpivid-v4l2" >> /boot/firmware/config.txt
sudo reboot
# create build directories
BUILD_DIR=~/build
mkdir -p $BUILD_DIR
# 1. Install kernel headers
KERNEL_VERSION=`uname -r | cut -d '-' -f 1`
KERNEL_REVISION=`uname -r | cut -d '-' -f 2`
sudo apt install linux-raspi-headers-$KERNEL_VERSION-$KERNEL_REVISION
cd /usr/src/linux-raspi-headers-$KERNEL_VERSION-$KERNEL_REVISION
sudo make headers_install INSTALL_HDR_PATH=$BUILD_DIR/linux-headers
# 2. Install build dependencies for ffmpeg
# Open /etc/apt/sources.list and uncomment all the deb-src entries
sudo apt update
sudo apt build-dep ffmpeg
# 3. Build modified ffmpeg by jc-kynesim
cd $BUILD_DIR
git clone https://github.com/jc-kynesim/rpi-ffmpeg.git
cd rpi-ffmpeg
git checkout dev/4.3.1/drm_prime_1
./configure --prefix=/opt/ffmpeg --libdir=/opt/ffmpeg/lib --incdir=/opt/ffmpeg/include --extra-cflags="-I${BUILD_DIR}/linux-headers/include -O3"\
--disable-stripping --disable-thumb --disable-mmal --enable-sand --enable-v4l2-request --enable-libdrm\
--enable-libudev --enable-shared --enable-libdrm --enable-libudev\
--enable-libx264 --enable-gpl
make -j4
# 4. Run your own tests using ffmpeg
sudo LD_LIBRARY_PATH=/opt/ffmpeg/lib /opt/ffmpeg/bin/ffmpeg -hwaccel drm -i hevc-input-file.mp4 -c:v h264_v4l2m2m -b:v 2000k h264-output-file.mp4
Limitations and Performance
Thanks to the great works of the community the decoder can now be used through the ffmpeg utility and it’s libavcodec framework. Unfortunately I initially couldn’t decode more than 7 frames per second with my sample Big Buck Bunny (3840*2160 resolution, 8bit) video file. Running the perf profiler pointed to the av_rpi_sand_to_planar_y8 and av_rpi_sand_to_planar_c8 functions. Those fully utilized a single cpu core. Meaning the HEVC decoding worked just fine, but some boiler plate code is actually using up the available resources.
What I wasn’t aware of is that most likely due to optimizations the HEVC decoder stores the frames in a different format in memory. The community has called this layout SAND (remember the –enable-sand option in the build script?). It basically splits the image into columns of 128 bytes and then stores those consecutively in memory. Of course some stride values also come into play.
The diagram below shows how the SAND layout with column width 128 looks like.
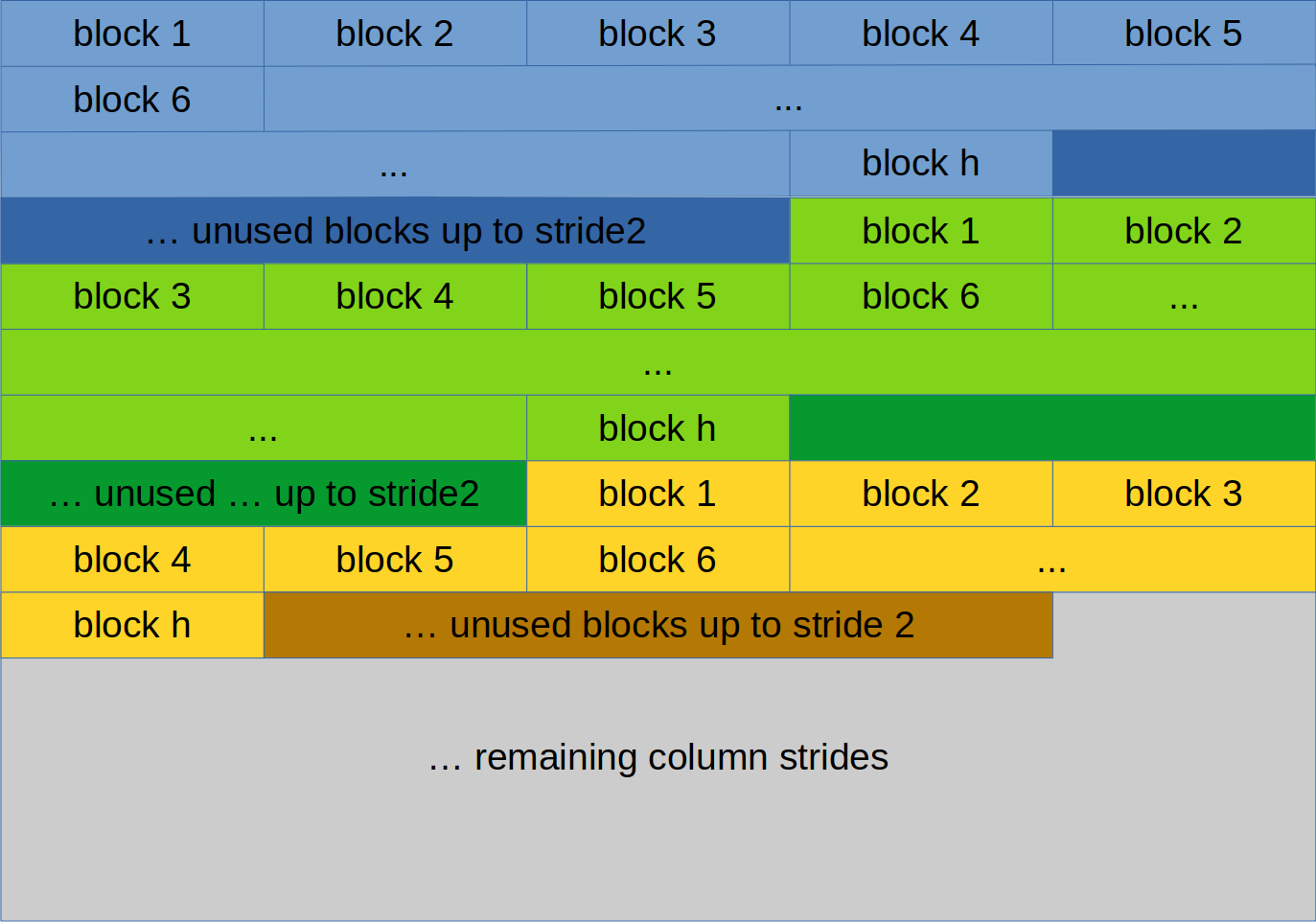
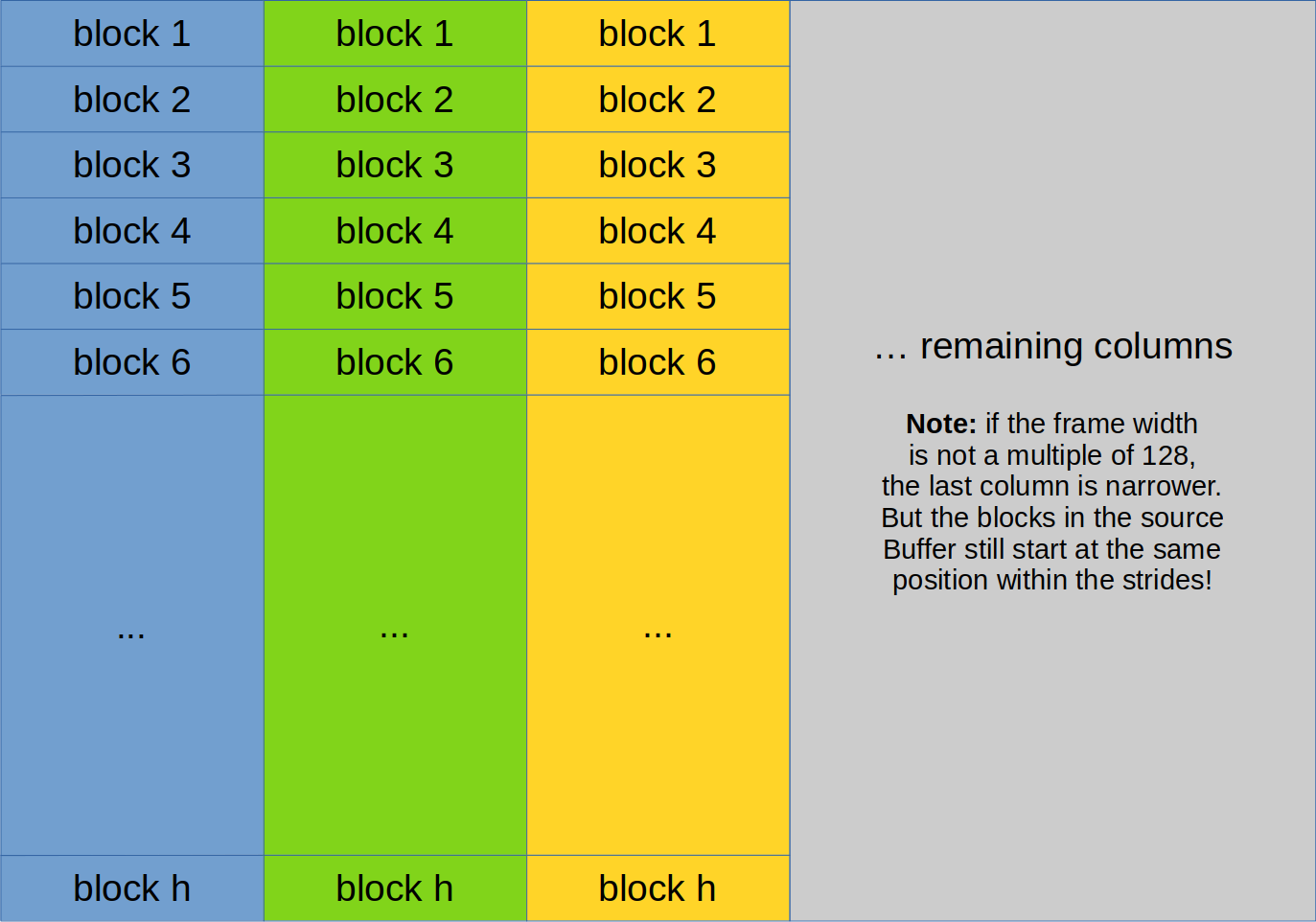
The frame data is stored using the YUV color encoding system. Meaning we have two buffers to decode. Both use the layout shown above, although when decoding the chrominance information, we have to split the values into U and V pixels. Also important is that the frame uses the YUV420 encoding, meaning both chrominance channels operate at a quarter of the resolution (half the width and height).
For those who would like some test data, I actually dumped a frame from the Big Buck Bunny film for my own tests. The files are available on: imgur.
To further process the frames a conversion to a planar frame layout is often necessary. Ffmpeg already is able to convert these frames as explained above. Unfortunately it uses a slow C based implementation on arm64. The RaspberryPI foundation has implemented an optimized version for arm32, but arm64 has to fall back to the slow default implementation. In order to improve the experience on arm64 I wrote an assembly version of this algorithm which I want to describe in more detail down below.
Arm64 Assembly
Now since I don’t write assembly code frequently, and in those rare cases usually for x86_64 I needed to gather some details first. Due to time restrictions I didn’t favour reading and working through a whole text book on arm64 assembly. This is why I used some online resources instead to quickly get the results I was looking for.
- A good introduction to aarch64 assembly development has been posted by Roger Ferrer Ibáñez over on his blog in a series of posts.
- Wikipedia has a good overview of the calling convetions and descriptions of which register we can use: Wikipedia: Calling convetion#ARM_(A64)
- The official documentation of the calling convention is available on ARM’s website.
- A nice cheat sheet with an instruction overview has been compiled by the University of Washington: cs.washington.edu
- A short presentation created by Matteo Franchin (Arm Ltd.) also gives an interesting quick overview.
- A blog post by Mathieu Garcia gives some input on how to use the vector instructions.
- And for the other cases where I didn’t know how to move on, I simply wrote a simple piece of C++ code and compiled it on godbolt.org. Simply set the compiler to “armv8-a clang 11.0.0” and add the argument “-O1” to enable basic optimizations. The resulting assembly code has the exact syntax (gnu assembler) which I needed to expand ffmpeg.
Some other notes: Be careful with what registers you use. The wikipedia article is quite good, but some other blog posts I came across during my research had conflicting details. In general you can use X9-X15 without any restrictions, X8 if you don’t have a return type, and X0-X7 if you don’t need to keep the arguments passed to your function. Other registers might be possible to be used, but have to be backuped onto the stack first. Vector registers V0-V7 and V16-V31 can also be freely used. V8-V15 have to be backuped onto the stack as well. Also interesting is that one can access the Xn 64bit registers as 32bit registers by simply using Wn instead. In those cases the lower 32bits are used and the instructions set the higher 32bits of the destination register to 0.
Converting the SAND Layout with Assembly
To ensure that I fully understood how the conversion works, I reimplemented the algorithm in C++. I chose C++ simply because that’s what I use at work and I’m most familiar with. After I had a well looking implementation I transferred exactly this logic to assembly code.
void sand2yuv_y8(const std::uint8_t *frame_src, std::uint8_t *dst, const std::uint32_t width,
const std::uint32_t height, const std::uint32_t stride2)
{
const std::uint32_t stride1 = 128;
const std::uint32_t block_wcount = width / stride1;
const std::uint32_t remaining_pixels = width - block_wcount * stride1;
const std::uint32_t offset_to_next_block = stride2*stride1 - stride1;
std::uint32_t row_start_offset = 0;
for (std::uint32_t row = 0; row < height; ++row)
{
const std::uint8_t *src = frame_src + row_start_offset;
for (std::uint32_t blockId = 0; blockId < block_wcount; ++blockId, src += offset_to_next_block)
{
for (std::uint32_t i = 0; i < stride1; ++i)
{
*dst++ = *src++;
}
}
for (std::uint32_t x = 0; x < remaining_pixels; ++x)
{
*dst++ = *src++;
}
row_start_offset += stride1;
}
}
/*
Copyright (c) 2021 Michael Eiler
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
* Neither the name of the copyright holder nor the
names of its contributors may be used to endorse or promote products
derived from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
Authors: Michael Eiler <eiler.mike@gmail.com>
*/
#include "asm.S"
// void ff_rpi_sand8_lines_to_planar_y8(
// uint8_t * dest, : x0
// unsigned int dst_stride, : w1
// const uint8_t * src, : x2
// unsigned int src_stride1, : w3, always 128
// unsigned int src_stride2, : w4
// unsigned int _x, : w5
// unsigned int y, : w6
// unsigned int _w, : w7
// unsigned int h); : [sp, #0]
function ff_rpi_sand8_lines_to_planar_y8, export=1
// w15 contains the number of rows we need to process
ldr w15, [sp, #0]
// w8 will contain the number of blocks per row
// w8 = floor(_w/stride1)
// stride1 is assumed to always be 128
mov w8, w1
lsr w8, w8, #7
// in case the width of the image is not a multiple of 128, there will
// be an incomplete block at the end of every row
// w9 contains the number of pixels stored within this block
// w9 = _w - w8 * 128
lsl w9, w8, #7
sub w9, w7, w9
// this is the value we have to add to the src pointer after reading a complete block
// it will move the address to the start of the next block
// w10 = stride2 * stride1 - stride1
mov w10, w4
lsl w10, w10, #7
sub w10, w10, #128
// w11 is the row offset, meaning the start offset of the first block of every collumn
// this will be increased with stride1 within every iteration of the row_loop
eor w11, w11, w11
// w12 = 0, processed row count
eor w12, w12, w12
row_loop:
// start of the first block within the current row
// x13 = row offset + src
mov x13, x2
add x13, x13, x11
// w14 = 0, processed block count
eor w14, w14, w14
block_loop:
// copy 128 bytes (a full block) into the vector registers v0-v7 and increase the src address by 128
// fortunately these aren't callee saved ones, meaning we don't need to backup them
ld1 { v0.16b, v1.16b, v2.16b, v3.16b}, [x13], #64
ld1 { v4.16b, v5.16b, v6.16b, v7.16b}, [x13], #64
// write these registers back to the destination vector and increase the dst address by 128
st1 { v0.16b, v1.16b, v2.16b, v3.16b }, [x0], #64
st1 { v4.16b, v5.16b, v6.16b, v7.16b }, [x0], #64
// move the source register to the beginning of the next block (x13 = src + block offset)
add x13, x13, x10
// increase the block counter
add w14, w14, #1
// continue with the block_loop if we haven't copied all full blocks yet
cmp w8, w14
bgt block_loop
// handle the last block at the end of each row
// at most 127 byte values copied from src to dst
eor w5, w5, w5 // i = 0
incomplete_block_loop_y8:
cmp w5, w9
bge incomplete_block_loop_end_y8
ldrb w6, [x13]
strb w6, [x0]
add x13, x13, #1
add x0, x0, #1
add w5, w5, #1
b incomplete_block_loop_y8
incomplete_block_loop_end_y8:
// increase the row offset by 128 (stride1)
add w11, w11, #128
// increment the row counter
add w12, w12, #1
// process the next row if we haven't finished yet
cmp w15, w12
bgt row_loop
ret
endfunc
// void ff_rpi_sand8_lines_to_planar_c8(
// uint8_t * dst_u, : x0
// unsigned int dst_stride_u, : w1 == width
// uint8_t * dst_v, : x2
// unsigned int dst_stride_v, : w3 == width
// const uint8_t * src, : x4
// unsigned int stride1, : w5 == 128
// unsigned int stride2, : w6
// unsigned int _x, : w7
// unsigned int y, : [sp, #0]
// unsigned int _w, : [sp, #8]
// unsigned int h); : [sp, #16]
function ff_rpi_sand8_lines_to_planar_c8, export=1
// w7 = width
ldr w7, [sp, #8]
// w15 contains the number of rows we need to process
ldr w15, [sp, #16]
// number of full blocks, w8 = _w / (stride1 >> 1) == _w / 64 == _w >> 6
mov w8, w7
lsr w8, w8, #6
// number of pixels in block at the end of every row
// w9 = _w - (w8 * 64)
lsl w9, w8, #6
sub w9, w7, w9
// address delta to the beginning of the next block
// w10 = (stride2 * stride1 - stride1) = stride2 * 128 - 128
lsl w10, w6, #7
sub w10, w10, #128
// w11 = row address start offset = 0
eor w11, w11, w11
// w12 = 0, row counter
eor w12, w12, w12
row_loop_c8:
// start of the first block within the current row
// x13 = row offset + src
mov x13, x4
add x13, x13, x11
// w14 = 0, processed block count
eor w14, w14, w14
block_loop_c8:
// load the full block -> 128 bytes, the block contains 64 interleaved U and V values
ld2 { v0.16b, v1.16b }, [x13], #32
ld2 { v2.16b, v3.16b }, [x13], #32
ld2 { v4.16b, v5.16b }, [x13], #32
ld2 { v6.16b, v7.16b }, [x13], #32
// swap register so that we can write them out with a single instruction
mov v16.16b, v1.16b
mov v17.16b, v3.16b
mov v18.16b, v5.16b
mov v1.16b, v2.16b
mov v2.16b, v4.16b
mov v3.16b, v6.16b
mov v4.16b, v16.16b
mov v5.16b, v17.16b
mov v6.16b, v18.16b
st1 { v0.16b, v1.16b, v2.16b, v3.16b }, [x0], #64
st1 { v4.16b, v5.16b, v6.16b, v7.16b }, [x2], #64
// increment row counter and move src to the beginning of the next block
add w14, w14, #1
add x13, x13, x10
// jump to block_loop_c8 iff the block count is smaller than the number of full blocks
cmp w8, w14
bgt block_loop_c8
// handle incomplete block at the end of every row
eor w5, w5, w5 // point counter, this might be
incomplete_block_loop_c8:
cmp w5, w9
bge incomplete_block_loop_end_c8
ldrb w1, [x13]
strb w1, [x0]
add x13, x13, #1
ldrb w1, [x13]
strb w1, [x2]
add x13, x13, #1
add x0, x0, #1
add x2, x2, #1
add w5, w5, #1
b incomplete_block_loop_c8
incomplete_block_loop_end_c8:
// increase row_offset by stride1
add w11, w11, #128
add w12, w12, #1
// jump to row_Loop_c8 iff the row count is small than the height
cmp w15, w12
bgt row_loop_c8
ret
endfunc
The implementation for the chrominance conversion looks almost exactly the same, except for the different vector instruction and some bit-shifts to accommodate for the interleaved UV values. The implementation is also shown at the bottom of the source code shown above.
Verdict and Open Questions
Now obviously the important question is how well this performs. I currently reach around 40fps when decoding the Big Buck Bunny film. Compared to the initial 7fps this is a significant improvement. Although I don’t expect this to be the final answer to HEVC decoding. I just sent these changes as a pull request to the ffmpeg fork maintainer, to receive some feedback. Once some news are available I will of course update this blog post. (Update: And only a single day later the changes have already been merged ;).)
Other questions are then afterwards of course what to do with the decoded frames. I’m interested in video transcoding, and the Raspberry PI 4 only has a 1080p h264 encoder. Meaning scaling the image down is a necessity. Obviously the CPU isn’t fast enough to do this well, meaning we would have to utilise the built-in ISP. Unfortunately I haven’t seen any progress in API support in that area yet.
Stay tuned for future updates on this topic, and hopefully other interesting topics on this blog ;-).
Update on the 11th of February
I spent some time on speeding up 10bit/hdr video decoding:
With these changes video files are current decoded and converted to planar frames with 16-18fps at 2160p. Still not fast enough for uhd transcoding but it should be good enough for lower resolution video. For playback alone accroding to jc-kynesim’s answers in the link above, the video output can be passed to the DRM subsystem directly, without the expensive conversion. Unfortunately for transcoding it looks like we might have reached the limitations of this SoC.