C++20: An Introduction. The Update We’ve All Been Waiting For?
A few months ago the ISO C++ standard committee has completed the newest revision of the C++ programming language and it’s companion the standard template library. As per usual they followed the mantra “good things take time” and focused on including well thought out extensions and improvements. Fortunately, a lot of these new additions have been in the making for many years, in which they were debated, refined and iterated upon. This has allowed C++20 to become a fantastic release, probably the largest one since 2011 - which marked the beginning of what we call modern C++.

Effective Modern C++ Scott Meyer has shown many ways of how to correctly utilise C++11/14 features and write modern C++ code. Last year the C++20 language and standard template library have been finalized. This, once more, will change what it means to develop modern C++ based software. (Vincent van Zalinge/unsplash)
In this blog post, some of the most notable changes are summarized in a concise way. The overview should give an idea of what’s to come with the next compiler and library updates and how future C++ projects might look like.
The Language
With library features we often see implementations early on in boost, libabseil, cppcoro and others, language features are harder to evaluate early in production projects. Some of the features below had preview implementations in one compiler or another, but portable code usually has to wait until the standard is finalized and the compilers are updated. The current three most significant language extensions concepts, modules and coroutines are on a good way but compiler support is not yet complete. A good and detailed overview is shown on cppreference.com. Fortunately all of these features are available in at least one of the most important compilers gcc, clang or msvc.
Concepts
Libraries like boost (and others of course) have long been plagued by dreadful compiler diagnostics. This has been mostly due to their significant usage of class and function templates. Concepts try to resolve this issue with the introduction of constraints for template parameters. This allows to do some type checking, improves the diagnostic output of compilers and replaces older complex workarounds based on type-traits and SFINAE.
#include <concepts>
template <typename T>
concept HasCoordinates = requires (T p) {
std::floating_point<decltype(p.x)>;
std::floating_point<decltype(p.y)>;
std::floating_point<decltype(p.z)>;
};
template <typename T>
requires std::movable<T> && std::default_initializable<T> && HasCoordinates<T>
class Octree
{
public:
/// Inserting a point into the octree. T has already been constrained on class level.
void insert(const T& point) { /* ... */ }
/// We want to check whether a set of coordinates is stored in the octree. For this it doesn't matter
/// whether the given point has type T. It just needs to provide cartesian coordinataes.
bool contains(const HasCoordinates auto& point) { /* ... */ return false; }
/// Another way of specifying the constraint.
template <HasCoordinates OtherPointT>
void remove(const OtherPointT& point) { /* ... */ }
/// A sample function making use of a requires expression to constrain the visitor template type.
template <typename VisitorT>
requires requires (VisitorT v, T p) { { v.visit(p) } -> std::same_as<void>; }
void visit(VisitorT& visitor) { /* ... */ }
};
Before going through the example above. We should clarify some naming details. What we call concept, is in fact a named set of constraints. Such a concept can consist of a combination of other concepts and additional requires-expressions. The standard template library defines a useful set of base concepts which are also used in the octree shown here. This is why it includes the concepts header in the first line. Starting on line three I defined a custom concept which consists of a a set of requires expressions. Their purpose is simply to ensure that whatever point type I use, the octree implementation can query it for Cartesian coordinates. This is done by reusing the predefined concept std::floating_point. The actual class definition afterwards specifies a few basic requirements for the point type. Let’s assume we store the points in a vector, this would require the point type to be movable and default initializable. All these requirements are specified by using predefined concepts combined with our own HasCoordinates concept.
Most of the member functions below show different variations of how to utilise constraints. Interesting is the visit template method on line 30. It uses a requires-expression to specify that the template argument must have a visit method, consuming our point and returning void. Notable details here are the duplicated requires keyword. The first being used to specify a constraint, the second to start the requires-expression. Specifying the void return type of the member function is actually optional and in this case just shown for demonstrative purposes.
For more information on concepts head over to cppreference or the very interesting post on requires-expressions by Andrzej Krzemieński.
Coroutines
Coroutines are a relatively old concept. In fact they were mentioned decades ago by Donald Knuth as a generalisation of functions. The idea from today’s perspective might sound simple enough, but as we know today Mr. Knuth was decades ahead with his thoughts. His idea was that a function should not be restricted to an entry and an exit point, but an arbitrary number of suspend or resume points. Now you might wonder why I would go back to the stone age of computer science. But please bear with me for one more moment.
When coroutines are discussed, I often find us developers immediately thinking about functionality utilising coroutines, rather than the mechanism behind those. In C++20 this mechanism to suspend functions, has been standardized. Generators, cooperative multitasking and other library functionality will be able to make use of this, but are NOT part of the current iteration of the standard template library.
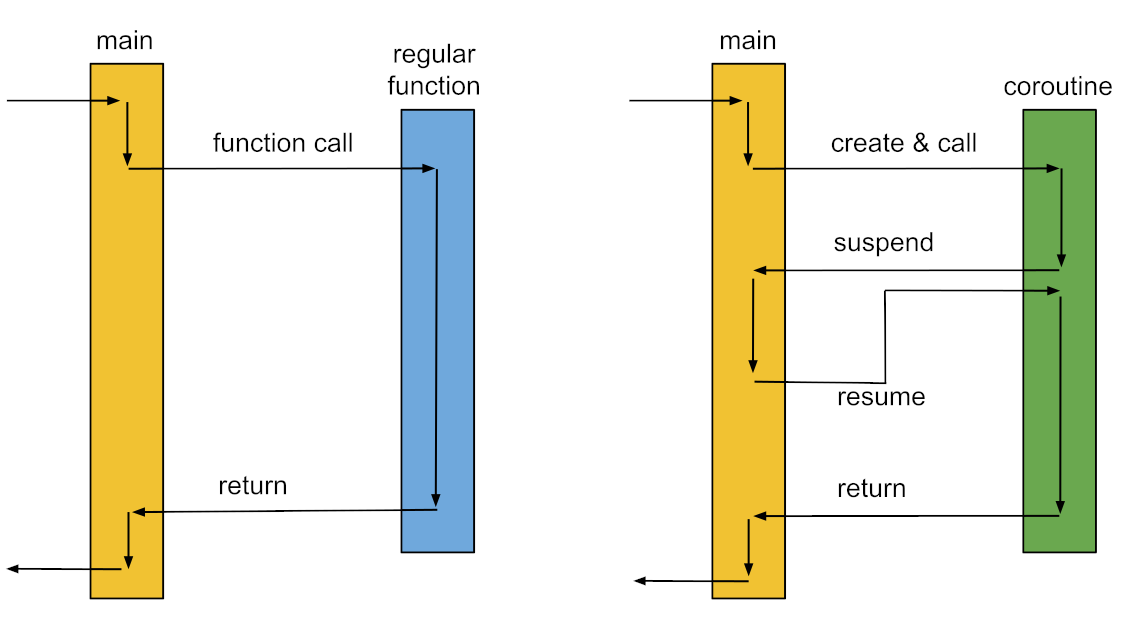
The mechanism to suspend a function can be implemented through different approaches. A common one in the past was to backup the registers and the instruction pointer as well as swap out the underlying stack. In fact boost::context, one of the best implementations of these kinds of coroutines, uses exactly this approach. Coroutines following this approach are usually called stackful coroutines or fibers. They offer an incredible flexibility but come with significant memory usage for the additional stack and a higher cost when calling or resuming the coroutine instance.
What C++20 has adopted are stackless coroutines. The major difference compared to fibers is that we are only able to suspend the coroutine from it’s own implementation body. Meaning we cannot suspend in a nested function we call from the coroutine. The reason for this is that we do not replace the stack, but only backup the variables in the current stack frame. This has the advantage of requiring none or very little additional memory and the actual cost and resume operations being about as cheap as a regular function call. This can lead to amazing performance results if this mechanism is used for things like asynchronous IO or more broadly cooperative multi-tasking. In fact libraries like boost::asio or std::network will likely end up using this mechanism too.
Having briefly mentioned the motivation and theory behind coroutines, let’s have a short look at the newly introduced operators and keywords. The most important one being co_await. It marks a function as a coroutine as soon as it appears at least once in a function body. When the function, or now coroutine is than executed it will suspend itself and pass the coroutine handle (std::coroutine_handle<>) to an Awaiter. The Awaiter defines how the coroutine will be resumed. In the example below, which utilises a fork of cppcoro, the handle is passed to a thread-pool.
#include <cppcoro/sync_wait.hpp>
#include <cppcoro/task.hpp>
#include <iostream>
#include <thread>
cppcoro::task<void> someOtherTask(cppcoro::static_thread_pool& threadPool)
{
co_await threadPool.schedule();
std::cout << "another thread: " << std::this_thread::get_id() << "\n";
}
int main()
{
std::cout << "main thread: " << std::this_thread::get_id() << "\n";
cppcoro::static_thread_pool threadPool(4);
auto task = someOtherTask(threadPool);
cppcoro::sync_wait(task);
}
I showed a simple example here on purpose, since going into the details of how to implement the thread-pool would go way beyond the scope of a single blog post. Also others have done that before in way more detail. Lewiss Baker for example has written an interesting piece on the co_await operator. From a library user perspective the most important aspect to remember, is that the function in the example turned into a coroutine because of the keyword co_await. Also, any code before the operator can but doesn’t have to be executed directly when we call the coroutine. This is actually defined by the task structure and it’s promise_type. The promise_type similar to the awaiter is yet another newly introduced concept, necessary to define the behaviour of a coroutine in detail.
And since this isn’t complicated enough, there are also another two keywords: co_yield and co_return. Like described on cppreference.com, they are based on co_await which is why I have shown it first. The major difference is that the coroutine handle isn’t passed on, but only suspended and we additionally can return a value. These are the keywords used for components like generators. Again an example based on cppcoro:
#include <cppcoro/generator.hpp>
#include <iostream>
cppcoro::generator<int> range(int start, int count)
{
for (int i = start; i < start + count; ++i)
{
std::cout << "About to yield " << i << "\n";
co_yield i;
}
}
int main()
{
auto values = range(0, 10);
for (const int& v : values)
{
std::cout << "Consuming " << v << "\n";
}
}
And that’s it, coroutines shown in two very simple application examples. For those who would like to get more familiar with the implementation behind these components, I recommend to read the articles by Lewiss Baker and some of the other countless blog posts on this topic. Another option, I usually enjoy, is to read through code of good examples. Next to the cppcoro library I recently also stumbled across the newer libcoro project by Josh Baldwin.
Modules
Calling functionality in another translation unit has traditionally been achieved by using the preprocessor directive #include. Which just tells the preprocessor to copy together a certain set of text files. Unfortunately this means that the compiler needs to parse a tremendous amount of code for every single translation unit. Modules are an approach to solve this problem but also come with other benefits and unfortunately lots of open questions. But without further ado let’s dive into an example:
/// main.cpp
import HelloModule;
int main()
{
hello::printGreeting();
}
/// HelloModule.ixx
/// module interface unit
export module HelloModule;
export namespace hello
{
void printGreeting();
}
/// HelloModule.cpp
/// module implementation unit
module;
#include <iostream>
module HelloModule;
void hello::printGreeting()
{
std::cout << "hello world\n";
}
The code shown above implements a basic module which is split into the module interface unit and the module implementation unit. The only exported symbols are the ones in the hello namespace because they have been marked as such. The export keyword can be used with any other symbol as well, including class templates and template functions. Consuming a module is done by adding an import statement.
While this covers the basic statements and a potential file-structure, some special considerations have to made. Including non-module aware header files is only possible when marking a file as a module with the module; statement in the first line and including them before the actual module definition starts.
While the code above compiles fine with the newest version of msvc, neither gcc nor clang have finalized modules support. There are also other issues. While msvc is well integrated into Visual Studio, other platforms making use of ninja, cmake or meson as their build systems face quite some challenges. Where in the past including the header file of a not yet compiled translation unit was not an issue - the order of the compilation of the modules is now defined by the import statements. Meaning a build system would first have to parse all code files to build up the dependency graph to determine the order in which to compile the translation units. Furthermore, I also haven’t read anything about binary distribution and dependency management. How do we integrate them into a package manager like conan/vcpkg? What do we release as API documentation? The module interface unit?
With all these questions unanswered I leave you with a few good resources on modules covering the already standardized details. Good tools will be vital for this feature to find traction in the industry, but with the modules just having been standardized, we will have to wait a bit longer for those to be ready for prime-time.
- An introduction article on the Microsoft C++ Team Blog: link
- A series of articles about Modules. Starting from an introduction all the way to explaining some of the issues in later installments of the series: [link1], [link2], [link3]
The STL
Ranges
Algorithms and data structures have been a corner stone of the STL for as long as I recall. One hardly finds a C++ developer who’s not familiar with at least the most common containers and how to use them with the help of iterators. But being this mature, new ideas have been thrown around in the meantime. Functional programming languages and others like C# (LINQ) feature convenient ways of composing algorithms. Combined with lazy evaluation this can be an efficient way to implement queries and other operations on containers.
The std::ranges proposal introduces these possibilities to C++20. The header introduces multiple so called views which can be chained to formulate queries.
#include <algorithm>
#include <ranges>
#include <iostream>
#include <vector>
#include "Song.h"
int main()
{
std::vector<Song> songs {
{ "Nek", "Laura non c'è", Genre::Pop, 7},
{ "Francesco Renga", "Il mio giorno più bello nel mondo", Genre::Pop, 10},
{ "Fort Minor", "Remember the Name", Genre::Rap, 6},
{ "Lorenz Büffel", "Johnny Däpp", Genre::ApreSki, -128},
{ "Dido", "White Flag", Genre::Pop, 10},
{ "Ed Sheeran", "South of the Border", Genre::Rap, 5}
};
std::ranges::sort(songs, [](const Song& s1, const Song& s2) { return s1.rating > s2.rating; });
auto isDecentSong = [](const Song& s) { return s.genre != Genre::ApreSki; };
auto hasGreatRating = [](const Song& s) { return s.rating > 5; };
auto goodSongsRange = songs | std::views::filter(isDecentSong) | std::views::filter(hasGreatRating) |
std::views::reverse | std::views::take(2);
for (const auto& s : goodSongsRange)
{
std::cout << s.artist << ": " << s.title << "\n";
}
}
/// Genre.h
#pragma once
#include <cstdint>
enum class Genre : std::uint32_t
{
Undefined = 0,
Pop,
Rap,
ApreSki
};
/// Song.h
#pragma once
#include "Genre.h"
#include <string>
struct Song
{
std::string artist;
std::string title;
Genre genre;
std::int8_t rating;
};
Filtering a list of songs to create a new playlist is just an example of how such a query could look like. The most important thing to realise here is that we only iterate through the song list once.
One remaining aspect of std::range is that it makes significant usage of concepts. Range itself is a concept which defines that a range has to have a begin and end iterator. Meaning a lot of these views can be used with many other non-STL data structures as well, as long as they satisfy the range concept.
std::format
A modern replacement for printf. A clean and type safe way of writing formatted output, a syntax familiar to those who have used python in the past and based on a well tested implementation: libfmt.
#include <iostream>
#include <format>
int main()
{
const std::string city = "Dornbirn";
const int year = 1999;
const std::string artist = "Eiffel 65";
const std::string title = "I'm Blue!";
std::cout << std::format("Good Evening {0}! Let's party like it's {1}!\n", city, year);
std::cout << "With one of our favourite songs:\n";
std::cout << std::format("Artist: {0:>40}\nTitle: {1:>41}\n", artist, title);
}
/* This code will print:
Good Evening Dornbirn! Let's party like it's 1999!
With one of our favourite songs:
Artist: Eiffel 65
Title: I'm Blue!
*/
The implementation which will ship with the major STL implementations will also contain a huge range of format options. Unfortunately the only way to test this code is to run libfmt and replace std::format with fmt::format. Neither libstdc++, nor libc++ and Microsoft’s C++ Runtime include support for this new feature. Although it will undoubtedly ship with all of them in due time.
Small Bits and Pieces
The complete list of new features and their current compiler support is available in detail on cppreference.com. Nevertheless some are particularly interesting which is why I want to mention them briefly.
- While creating constexpr functions has been possible for some time, ensuring that they are actually executed at compile time was not. The new keyword consteval and constinit take care of this: link1, link2
- Designated initializers for structures: link
- Templated lambda expressions: link
- Bit operations: link
- Mathematical constants: link
- Calendar and time zones. link1, link2
- Dedicated types to store utf-8 encoded strings: char8_t and u8string. Unfortunately I mention these more because it looks like it might not be a good idea to use them: link
And much more of course. This list isn’t even close to being complete.
Conclusion & Outlook
Ever since reading about the coroutines and concepts proposals, I couldn’t wait for these features to finally land in the standard. With concepts, projects making use of a lot of templates, will be significantly easier to deal with. Coroutines are a feature which will allow us to implement generators and asynchronous programming in efficient, elegant ways we weren’t able to before. While modules could be equally impressive, their tooling situation is unclear and it remains to be seen how long it will take them to find any adoption.
Having such a huge release of course also raises the question of what’s next? Is there something left we would want to have in the standard? Yes, indeed! The executers and std::network proposals have not made it into the standard and are queued for the C++23 release. Fortunately, for those who need such functionality, boost and asio will likely ship such solutions before they make their ways into the STL.