C++20: Building a Thread-Pool With Coroutines

Introduction
Recently I’ve been rambling about the amazing improvements which will land with C++20 support in our toolchains. For those who haven’t had a look at those yet, I recommend checking out the summary in the following recent blog post: C++20: An Introduction. The Update We’ve All Been Waiting For?.
While the article gives an interesting overview on the most important features of the new release, I didn’t go into the details of coroutines. An introduction to those can easily fill up multiple book chapters. In this article I’ll try to document my experience with implementing a simple thread-pool. The thread-pool is based on the concepts and ideas of the cppcoro library developed by Lewiss Baker. Reimplemented and stripped down to the bare minimum, in order to explain the most important aspects of coroutines.
As always starting with a refresher of the theory can’t harm. The diagram below visualizes the differences between procedures and the more generic approach of coroutines. Adding the suspend and resume functionality allows us to implement certain concepts - like thread-pools, state machines, generators and many others - in way more elegant and efficient ways.
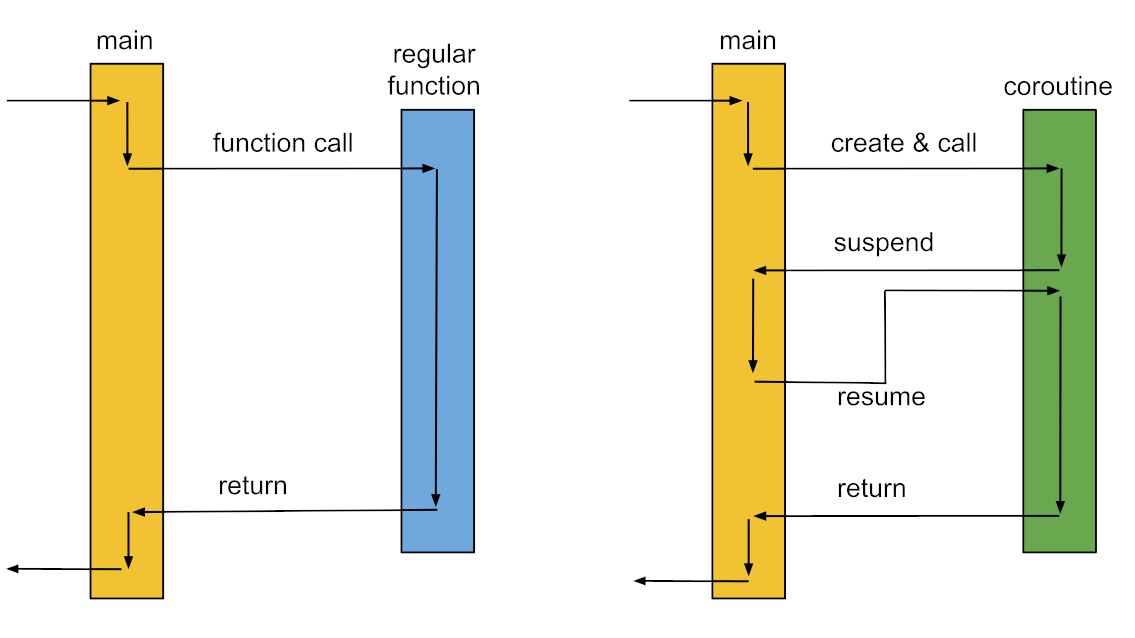
Of course the additional functionality compared to regular procedures requires some additional considerations. The local variables need to be copied to a separate portion of memory upon suspension and restored upon resuming the coroutine. An additional portion of memory for the coroutine data needs to be allocated and destroyed at some point. Fortunately all of these steps are handled by the compiler. The overall concept of this approach is called stack-less coroutines - in contrast to stackful coroutines where the full stack is swapped out. The latter have been available for some time in libraries like boost::context since they do not require compiler and language changes. Stack-less coroutines were introduced because they have, amongst others, efficiency benefits over their counterparts. One important advantage is the memory usage which is several magnitudes less.
In C++20 these stack-less coroutines consist of a varying set of concepts and customization options. The rest of this blog post will explain them as we go through implementing a thread-pool.
Fundamentals
The Coroutine
Syntactically a coroutine doesn’t vary vastly from a regular function. The main difference is in it’s return type requirements and in the fact that it needs at least one of the following keywords in it’s implementation body: co_await, co_yield or co_return. The following part shows our test coroutine. It schedules itself on our thread-pool and once continued by another thread, prints the thread id.
task run_async_print(threadpool& pool)
{
co_await pool.schedule();
std::cout << "This is a hello from thread: "
<< std::this_thread::get_id() << "\n";
}
With the co_await expression we suspend the coroutine. The argument for this keyword has to be either an awaitable (object implementing the co_await operator), an awaitable expression or an object which can be converted to an awaitable. All of these approaches have in common that the end result is an awaiter instance. The awaiter describes the behaviour of the suspend as well as the resume operation once the execution of the coroutine should continue. For our example this means our coroutine will be suspended and picked up by the thread-pool through the awaiter. The so called return object task is returned to the creator of the coroutine. The purpose for the creator is to interact with the coroutine. Retrieve potential results or simply wait for it to complete and destroy the coroutine in the end.
The Return Object and Promise Type
Before we continue with the awaiters and the actual thread-pool, we should have a look at the return object and it’s companion, the promise type. Both of them are equally important for good reasons. While the return object task, is important because it is used for the interaction with the creator of the coroutine, the promise type task_promise is important as the point of interaction for all the code generated by the compiler.
struct task_promise
{
task get_return_object() noexcept {
return task{ std::coroutine_handle<task_promise>::from_promise(*this) };
};
std::suspend_never initial_suspend() const noexcept { return {}; }
std::suspend_never final_suspend() const noexcept { return {}; }
void return_void() noexcept {}
void unhandled_exception() noexcept {
std::cerr << "Unhandled exception caught...\n";
exit(1);
}
};
The promise type, in this case called task_promise is where we specify what happens when we initially create the coroutine. We also specify what’s going to happened upon it’s completion. The initial_suspend describes whether the code until the first co_* call in the coroutine is executed upon creation or once the resume operation is executed for the first time. Think about a generator (or enumerator) where you would most likely call next() before you expect the first item to be available. Meaning upon the creation we would not execute any code within the coroutine. In such cases we return std::suspend_always to tell the compiler not to execute any code before we resume the coroutine for the first time. In our case we are at a step where we want to have to easiest possible thread-pool implementation, meaning we want to immediately schedule the coroutine on the thread-pool by executing all code including the co_await expression upon the creation of the task. This is why we return std::suspend_never for now. We will later change this for another good reason, but for now this is good enough.
The final_suspend call on the other hand describes whether upon completing the execution, the coroutine should suspend one more time or whether it should be destroyed. For the first iteration of this example we can go with the simple solution and return std::suspend_never.
Some additional methods need to be implemented as well. The method get_return_object does exactly what it says, it creates our task object. The interesting detail here is that we retrieve the std::coroutine_handle<> which is what is used to resume the coroutine. This is then passed on to the task object. Further required methods are return_void and unhandled_exception. While the latter on is self-explanatory, return_void is more interesting. It is either called upon completing the coroutine without any special operations, like exiting a implementation body at it’s tail, or when executing co_return; to complete the coroutine early.
Note: Having mentioned the co_return keyword, although not of importance for these examples, we should also mention
co_yield. Both of these are simplifications around co_await, for scenarios where a simple suspend is enough and a potential resume is triggered manually by the creator of the coroutine. An application example is a generator, where we suspend once we generated a new value, and resume upon requesting the next item. For more information on these two keywords, check out the generator implementation by Lewiss.
As already mentioned the companion of the promise type is the return object. This is the object returned to the creator of the coroutine. In case of our task it could have a blocking functionality (e.g. wait) to wait for it’s completion, or methods to retrieve potential result values. Nevertheless for our initial example, which we will iterate upon, none of these are added. The only strict requirement by the compiler, is to give it a hint on what the promise type is. Because if we recall, the coroutine only specified the return type task, but the compiler needs to know what the type of the corresponding promise type is. This is done by adding a public using declaration called promise_type pointing to the actual class.
class [[nodiscard]] task
{
public:
using promise_type = task_promise;
explicit task(std::coroutine_handle<task_promise> handle)
: m_handle(handle)
{
}
private:
std::coroutine_handle<task_promise> m_handle;
};
While the version of our first task class iteration doesn’t have any important functionality, some aspects are nevertheless interesting. You might recall that we returned std::suspend_never as the final_suspend call in our promise type. Meaning the coroutine is automatically destroyed. The alternative would have been to return std::suspend_always and destroy it in the destructor of the task class. Also note that our class has a [[nodiscard]] attribute added to it’s definition. This will be quite important later on when the task object controls the life time of the coroutine. In general I suggest to always add the attribute to a return type object, as controlling the life time of the coroutine is usually the norm, rather than the exception. For our initial version this will be good enough, but we will come back to these discussions in later sections.
The Thread-Pool and Awaiters
In order to break everything down to the most basic components, let’s have a look at the base structure of our thread-pool class first. What you see below is a most basic implementation having some threads in the background waiting on a queue to execute tasks, or in our case resume coroutines. Even without coroutines a simple thread_loop implementation wouldn’t have looked much different. Instead of the coroutines we would simply have stored std::function instances in a queue instead. Interesting here is only the fact that we use the std::coroutine_handle to interact with the coroutine. Specifically the resume() call in the thread loop is important. Once the coroutine is completed, it will automatically be destroyed and we can wait for the next one within the queue.
class threadpool
{
public:
// ...
auto schedule()
{
// ... here we've got to return the awaiter I mentioned earlier
}
private:
std::queue<std::coroutine_handle<>> m_coros;
// ...
void thread_loop()
{
while (!m_stop_thread)
{
std::unique_lock<std::mutex> lock(m_mutex);
// ... waiting for a task, checking for stop requests
auto coro = m_coros.front();
m_coros.pop();
lock.unlock();
coro.resume();
}
}
void enqueue_task(std::couroutine_handle<> coro) noexcept {
std::unique_lock<std::mutex> lock(m_mutex);
m_coros.emplace(coro);
m_cond.notify_one();
}
};
If we had used std::function to wrap up tasks and schedule them on the thread-pool we likely would have passed them to the schedule method. With coroutines we have to create an awaiter instead which takes over this functionality. While this initially might look like inconvenient, in fact this approach allows a multitude of customization possibilities.
auto schedule()
{
struct awaiter
{
threadpool* m_threadpool;
constexpr bool await_ready() const noexcept { return false; }
constexpr void await_resume() const noexcept { }
void await_suspend(std::coroutine_handle<> coro) const noexcept {
m_threadpool->enqueue_task(coro);
}
};
return awaiter{this};
}
The awaiter concept specifies that an implementation must have three different methods. The first await_ready is a shortcut we could use in case it is not necessary to resume the coroutine. Either it already has been destroyed or would immediately suspend again anyway. In these examples we always return false, but some use cases might benefit from this optimization possibility. The more interesting two methods are await_suspend and await_resume. The latter one is called upon resuming the coroutine and allows to specify a return type for the co_await expression by changing it’s return type. It’s sibling await_suspend is called during the suspension of a coroutine instead. It takes the coroutine handle as an argument and is free to do whatever we can come up with. In our case we simply enqueue it into the thread-pool. There is also an option to return another coroutine handle within this function, which would cause the thread to continue with the execution of that coroutine instead. We will later use this functionality to implement continuations.
First Results
Now that we have all the necessary components ready, we can execute them for the first time. The full examples can be found here: https://gist.github.com/MichaEiler/b13771a9e0e403d8a0a082072fd14d68
Note: For these examples you will need to have GCC version 10. Later on we will required the even newer version 11. Fedora 34 might be an easy way to test out these new compilers. Alternatively using the newest version of Visual Studio should work as well, according to the compiler support page on cppreference.com. That said, I haven’t tested it.
To give an idea of what we are going to execute, let’s briefly have a look at the main function.
int main()
{
std::cout << "The main thread id is: " << std::this_thread::get_id() << "\n";
threadpool pool{8};
task t = run_async_print(pool);
std::this_thread::sleep_for(std::chrono::microseconds(1000));
}
After compiling and executing the binary you should be greeted with the following output. The proof that our first iteration does what we expect it to. The main thread id is printed as well as the id of the thread on which we resume the coroutine.
[michael@localhost]$ ./coro-sample
The main thread id is: 139925802370880
This is a hello from thread: 139925743617600
Extensions
Whereas the example above is good enough to explain the concepts there are still some basic requirements for a working thread-pool left. Simply firing off some work and never knowing about it’s successful completion is a rather irresponsible approach. Enough to show how the basic coroutine functionality can be utilised, but nothing more. The next few sections will address some of these shortcomings.
Continuations
A lot of the functionality we want to implement depends on being able to execute some custom code after the completion of the coroutine. In the implementations I’ve come across on Github (e.g. cppcoro and libcoro) this is solved by adding support for continuations. A continuation is another coroutine which is resumed after the completion of the original one.
In order to achieve this, one approach is to modify the promise- and return types of our coroutine. We start of with the promise-type where we have to store the continuation as well as make sure that it is resumed upon completion of the coroutine belonging to the promise-type.
struct task_promise
{
struct final_awaitable
{
bool await_ready() const noexcept { return false; }
std::coroutine_handle<> await_suspend(std::coroutine_handle<task_promise> coro) noexcept
{
return coro.promise().m_continuation;
}
void await_resume() noexcept {}
};
task get_return_object() noexcept;
std::suspend_always initial_suspend() const noexcept { return {}; }
auto final_suspend() const noexcept { return final_awaitable(); }
void return_void() noexcept {}
void unhandled_exception() noexcept { exit(1); }
void set_continuation(std::coroutine_handle<> continuation) noexcept
{
m_continuation = continuation;
}
private:
std::coroutine_handle<> m_continuation = std::noop_coroutine();
};
While the method to store the continuation is rather obvious, two additional changes are of importance here. At first it should be noted that std::suspend_never and std::suspend_always are actually awaiters themselves. The only difference between them is what await_ready returns. For us this is important because we can implement our own awaiter and therefore control the final suspend. The final_awaiter class has a custom await_suspend implementation which is called with the coroutine’s handle as argument. The method will then retrieve it’s promise type and the continuation we stored earlier on. By returning it the thread suspending the original coroutine will execute the continuation until it itself will suspend or complete. The second important change is the return type of initial_suspend which is changed to std::suspend_always. We cannot immediately execute our tasks anymore. In case we set a continuation we have to do that before we start the execution of the coroutine, otherwise we would create a race condition.
With the promise type we only upgraded one side of the coin. The return object task needs to be updated as well.
class [[nodiscard]] task
{
public:
using promise_type = task_promise;
explicit task(std::coroutine_handle<task_promise> handle)
: m_handle(handle)
{
}
~task()
{
if (m_handle)
{
m_handle.destroy();
}
}
auto operator co_await() noexcept
{
struct awaiter
{
bool await_ready() const noexcept { return !m_coro || m_coro.done(); }
std::coroutine_handle<> await_suspend( std::coroutine_handle<> awaiting_coroutine) noexcept {
m_coro.promise().set_continuation(awaiting_coroutine);
return m_coro;
}
void await_resume() noexcept {}
std::coroutine_handle<task_promise> m_coro;
};
return awaiter{m_handle};
}
private:
std::coroutine_handle<task_promise> m_handle;
};
The first important task is that we have to destroy the coroutine manually since we don’t let the compiler do it for us anymore. This is easily done in the destructor of the task object. The second part is that somehow we need to get the handle of a suspended coroutine which we can set as continuation. Meaning we have to use a co_await expression. In contrast to the schedule call in the first part of the blog post we don’t use an awaitable expression but make the task an awaitable by implementing the co_await operator. But as explained initially the end-result is the same. We have to return an awaiter instance. This awaiter takes the handle of the continuation and set’s it on the promise of our original coroutine. It then returns the original coroutine handle so that it is resumed automatically once we registered a continuation.
Synchronisation
In this example the purpose of the continuation is to set an event upon the completed execution of a coroutine. With C++20 we have the functionality to use wait and notify on std::atomic_flag which allows us to implement such an event very efficiently:
struct fire_once_event
{
void set()
{
m_flag.test_and_set();
m_flag.notify_all();
}
void wait()
{
m_flag.wait(false);
}
private:
std::atomic_flag m_flag;
};
Unfortunately one needs at least version 11 of gcc to use the std::atomic_flag extensions, otherwise one would have to implement such an event based on std::mutex and std::condition_variable instead (or a futex if platform dependency isn’t an issue). Now that we have the continuation support, made the task class an awaitable and have an event as well, we can continue with the blocking functionality. In order to use the awaitable and register a continuation we will have to create a second coroutine. The task of this coroutine will be to await the execution the original task and set the event upon it’s completion. The actual coroutine therefore is also extremely short:
sync_wait_task make_sync_wait_task(task& t)
{
co_await t;
}
The co_await retrieves the awaiter from the awaitable task and registers itself as a continuation. By co_await-ing the task, the original coroutine will be resumed and reach it’s own first co_await expression. That expression will suspend the original coroutine again and schedule itself on the thread-pool. With the task being scheduled, the code within our second coroutine is already completed and the remaining actions are handled through it’s return object and promise type.
struct sync_wait_task_promise
{
std::suspend_always initial_suspend() const noexcept { return {}; }
auto final_suspend() const noexcept
{
struct awaiter
{
bool await_ready() const noexcept { return false; }
void await_suspend(std::coroutine_handle<sync_wait_task_promise> coro) const noexcept
{
fire_once_event *const event = coro.promise().m_event;
if (event)
{
event->set();
}
}
void await_resume() noexcept {}
};
return awaiter();
}
fire_once_event *m_event = nullptr;
sync_wait_task get_return_object() noexcept
{
return sync_wait_task{ std::coroutine_handle<sync_wait_task_promise>::from_promise(*this) };
}
void unhandled_exception() noexcept { exit(1); }
};
While the base structure should look familiar compared to the already presented task_promise, the devil’s in the details. It is crucially important to return std::suspend_always from initial_suspend. We wouldn’t want to co_await the original coroutine immediately. As you see, our sync_wait_task_promise has an event member which we should initialize first. Therefore we create the sync_wait_task (coroutine), store an event reference in it’s member and will only then resume the coroutine through the sync_wait_task return object below:
struct [[nodiscard]] sync_wait_task
{
using promise_type = sync_wait_task_promise;
sync_wait_task(std::coroutine_handle<sync_wait_task_promise> coro)
: m_handle(coro)
{
}
~sync_wait_task()
{
if (m_handle)
{
m_handle.destroy();
}
}
void run(fire_once_event& event);
private:
std::coroutine_handle<sync_wait_task_promise> m_handle;
};
inline void sync_wait_task::run(fire_once_event& event)
{
m_handle.promise().m_event = &event;
m_handle.resume();
}
inline void sync_wait(task& t)
{
fire_once_event event;
auto wait_task = make_sync_wait_task(t);
wait_task.run(event);
event.wait();
}
The task structure is actually straight forward, with the only significant difference compared to the task structure being the run method. The run method sets the event reference and then resumes the coroutine. The coroutine now finally co_awaits the actual task, which in turn resumes the original coroutine and schedules it on the thread-pool. With having invoked all program code we can finally wait for the completion using the event. This is all wrapped up in the sync_wait function.
Results
The main function has only one different line. Instead of sleeping for a second and praying that our task has completed, we can block and wait for the completion.
int main()
{
std::cout << "The main thread id is: " << std::this_thread::get_id() << "\n";
threadpool pool{8};
task t = run_async_print(pool);
sync_wait(t);
}
If nothing went wrong, you should the see the familiar output again:
[michael@localhost]$ ./coro-sample
The main thread id is: 139993217763136
This is a hello from thread: 139993159009856
The code for the completed example can be found here: https://gist.github.com/MichaEiler/99c3ed529d4fd19c4289fd04672a1a7c
Final Words
I want to mention the amazing work done by Lewiss Baker. His library cppcoro is an extremely good reference. It allowed me to understand the concepts myself, and then use that knowledge to implement and compare my own thread-pool against his. I checked multiple times on how he implemented some details in order to avoid race conditions. Additionally the library has loads of additional features which one needs in an actual industrial or open source project.
The goal of this blog post was to document and explain coroutines using a relatively simple example. In case some of you find any mistakes or have suggestions for improvements, feel free to get into contact through LinkedIn.